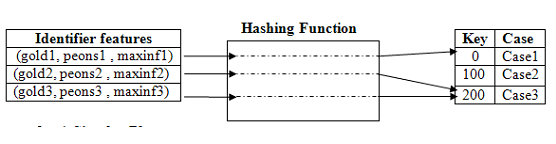
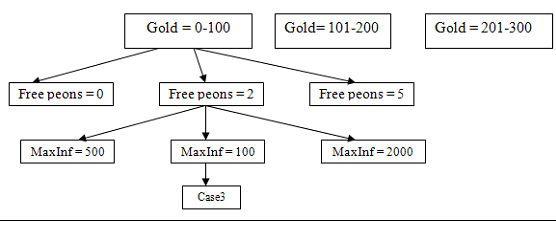
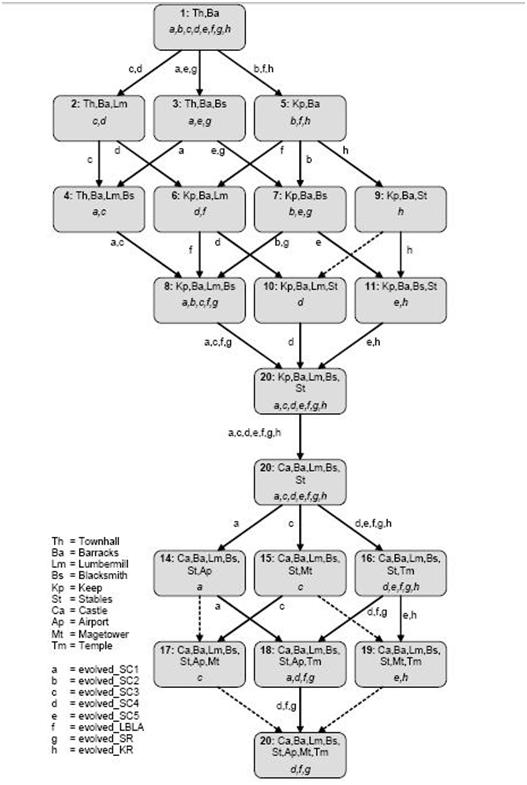
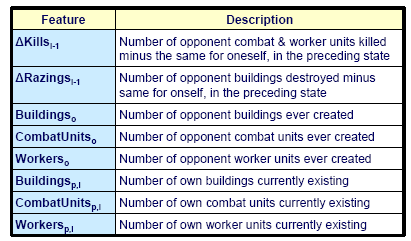
Traditionally, in Case-Based Reasoning the process of case retrieval is done by selecting the case from the case-base that has the closest similarity to the world state of the problem. This similarity is measured over the various features that are computed from the representation of the world state.
Omar asked “How will you determine the importance of a feature?”
This paper : Situation Assessment for Case Retrieval by Kinshuk Mishra, Santiago Ontan˜on, and Ashwin Ram answers this question as follows:
The importance of features depends on their relevance in representing the high-level world state, this is high level game state is defined here as a Situation. For example, in the WARGUS domain the player might be in an attacking situation, or in a base building situation among others. Situations can be predicted based on the raw features that are directly computed from the world state i.e. shallow features.
THUS, Situation assessment is a process of gathering high-level information using low-level data to help in better decision making.
The general situation assessment algorithm is described in Figure 3. It comprises of four main steps:
1- Shallow feature selection
a. Given situation annotated trace T is provided to a feature selection algorithm. This algorithm returns the set of shallow features which have high information gain. Specifically, in Darmok, we have used best-first greedy hill-climbing algorithm for filtering the high information gain shallow features.
2- Model Generation.
a. The Situation-Classification Model Mcf
This model is useful for classification of a world state to a situation using shallow features. In Darmok, we have used a standard algorithm inducing a decision tree classifier model.
b. The Situation-Case Model Mc
Provides a mapping from the set of situations S to a subset of cases in the case-base C. It can be built using statistical or empirical analysis.
c. The Situation-Deep feature Model Mdf
Provides a mapping from S to deep features in the set Fd. This mapping is done using a feature selection algorithm or by using empirical knowledge.
3- Model Execution.
In this third step, the models generated in the previous step are executed to get the current situation S, the subset of cases C’ from the case-base C and the subset of deep features Fd’ which are most relevant to S. S is obtained by running Mcf over Fs’. Once S is known, using Mc and Mdf , C ‘ and Fd’ are obtained respectively.
4- Case Retrieval.
This is the last step where using Fd’ and FS the most similar case in retrieved from C’ using normal retrieval techniques.