-
Abstract:
- Traditional artificial intelligence techniques do not perform well in applications such as real-time strategy games because of the extensive search spaces which need to be explored. In addition, this exploration must be carried out on-line during performance time; it cannot be precomputed. We have developed on-line case-based planning techniques that are effective in such domains. In this paper, we extend our earlier work using ideas from traditional planning to inform the real-time adaptation of plans. In our framework, when a plan is retrieved, a plan dependency graph is inferred to capture the relations between actions in the plan. The plan is then adapted in real-time using its plan dependency graph. This allows the system to create and adapt plans in an efficient and effective manner while performing the task. The approach is evaluated using WARGUS, a well-known real-time strategy game.

-
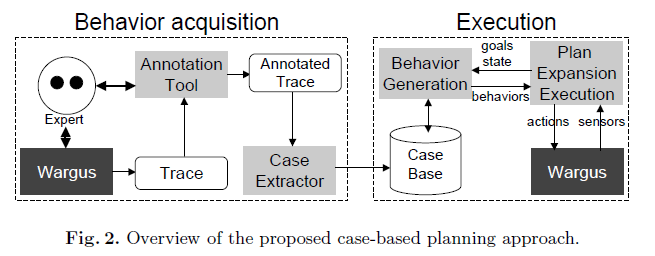
A key problem in CBP is plan adaptation;
- Plans cannot be replayed exactly as they were stored, especially in games of the complexity of modern RTS games.
- More specifically, CBP techniques for RTS games need adaptation techniques that are suitable for dynamic and unpredictable domains.
-
Plan adaptation techniques can be classified in two categories:
- Those adaptation techniques based on domain specific rules (domain specific, but fast)
- Those based on domain independent search-based techniques (domain independent, but slow)
- However, most previous work on plan adaptation focus on one-shot adaptation where a single plan or set of plans are retrieved and adapted before execution. In this paper we are interested on developing domain independent and search-free plan adaptation techniques that can be interleaved with execution and that are suitable for RTS games.
-
Our plan adaptation technique is based on two ideas:
- Removing useless operations from a plan can be done by analyzing a dependency graph without performing search.
- The insertion of new operations in the plan can be delegated to the case-base planning cycle itself, thus also getting rid of the search.
- A goal is a symbolic non-operational description of the goal, while success conditions are actual predicates that can be checked in the game state to evaluate whether a goal was satisfied or not.
- Postconditions are conditions to be expected after a behavior executes while success conditions are the conditions that when satisfied we can consider the behavior to have completed its execution
- A partial plan tree in our framework is represented as a tree consisting of two types of nodes: goals and behaviors (notice the similarity with HTN planning (Nau et al. 2005)).
- While execution, basic actions that are ready and with all its preconditions satisfied are sent to WARGUS to be executed. If the preconditions are not satisfied, the behavior is sent back to the adaptation module to see if the plan can be repaired. If it cannot, then the behavior is marked as failed.
-
The plan adaptation module is divided in two submodules:
-
The parameter adaptation module.
- The first one is in charge of adapting the parameters of the basic actions, i.e. the coordinates and specific units
- The structural plan adaptation module.
-
-
Plans are composed of four basic types of elements:
-
Actions:
- Which are the basic actions that can be executed
-
Parallel plans:
- Which consist of component plans which can be executed in parallel
-
Sequential plans:
- Which consist of component plans which need to be executed in sequence
-
Sub-goal plans:
- Requiring further expansion.
-
- We can further deduce dependencies between different plans using their preconditions and success conditions.
- We specifically consider only plans which are completely expanded and do not contain a subgoal which further needs to be expanded.
- We generate a plan dependency graph using the preconditions and success conditions of the actions. This plan dependency graph informs the plan adaptation process.
-
Plan Dependency Graph Generator:
-
The plan dependency graph generation, begins by taking the success conditions of the root of the plan and finding out which of the component actions in the plan contribute to the achievement of these success conditions.
- These actions are called direct sub-plans for the subgoal.
- All direct sub-plans are added to the plan dependency graph.
- Then, the plan dependency graph generator analyzes the preconditions of each of these direct sub-plans.
-
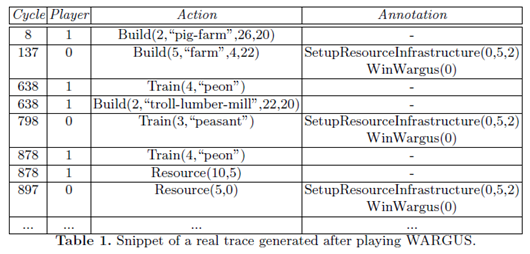
Let B1 be an action in the plan which contributes to satisfying the preconditions of a direct sub-plan D1. Then, it adds B1 to the plan dependency graph and forms a directed edge from B1 to D1.
- This directed edge can be considered as a dependency between B1 and D1.
- This is done for each of the direct sub-plans.
- Further this is repeated for each of the actions which are added to the graph.
- The generation stops when there’s more nodes are added to it.
- This process results in the formation of a plan dependency graph with directed edges between actions representing that one action contributes to the achievement of the preconditions of another action.
-
- However, a challenge in our work is that simple comparison of preconditions of a plan P1 with success conditions of another plan P2 is not sufficient to determine whether P2 contributes to achievement of preconditions of P1. This is because there isn’t necessarily a direct correspondence between preconditions and success.
- An example is the case where P1 has a precondition testing the existence of a single unit of a particular type. However, P2 may have a success condition testing the existence of a given number n of units of the same type. An edge should clearly be formed from P2 to P1, however a direct comparison of the conditions will not yield this relation.
- For that purpose, the plan dependency graph generation component needs a precondition-success condition matcher (ps-matcher). In our system, we have developed a rule-based ps-matcher that incorporates a collection of rules for the appropriate condition matching.
- If a dependency was not detected by our system, a necessary action in the plan might get deleted. However, if our system adds extra dependencies that do not exist the only thing that can happen is that the system ends up executing some extra actions that would not be required. Clearly, executing extra actions is better than missing some needed actions.
-
The plan adaptation following the creation of the plan dependency graph has two sub-processes:
- Elimination of unnecessary actions.
- Insertion of extra actions.
- The first one is performed as soon as the plan is retrieved, and the second one is performed on-line as the plan executes.
-
Removal of unnecessary actions:
-
Given a plan for a goal, the plan dependency graph is generated and the success conditions of each direct plan are evaluated for the game state at that point of execution.
- This gives a list L of direct plans whose all success conditions are satisfied and hence do not need to be executed.
- Now, consider L as the list of actions that can be removed from the plan corresponding to the plan dependency graph.
- All actions B which are present only on paths terminating on an action D such that D L can be removed and hence can be added to L.
- This is repeated until L becomes stable and no new plan is added to it.
- All actions in L are removed from the plan dependency graph.
- The resulting plan dependency graph has only those actions whose success conditions are not satisfied in the given game state and which have a path to a direct plan, also with success conditions not satisfied in the given game state.
-
-
Adaptation for unsatisfied preconditions:
- If the execution of an action fails because one or more of its preconditions are not satisfied, the system needs to create a game state where the given preconditions are satisfied so that the execution of the plan can proceed.
- To enable this, the adaptation module inserts satisfying goals in the plan (one goal per unsatisfied precondition).
- The satisfying goals are such that when plans to achieve the goals is retrieved and executed, the success of the plans implies that the preconditions of the failed action are satisfied.
- Example: When an action P1 fails to proceed because a precondition C1 is not satisfied, a satisfying goal G1 for C1 is formed. P1 is replaced by a sequential plan containing a subgoal plan with goal G1 followed by P1.
-
Notice that the plan adaptation module performs two basic operations:
- Delete unnecessary actions (which is performed by an analysis of the plan dependency graph)
-
Insert additional actions needed to satisfy unsatisfied preconditions.
-
This last process is performed as collaboration between several modules:
- The plan execution module: identifies actions that cannot be executed
-
Then, the adaptation component:
- Identifies the failed preconditions
- And generates goals for them
- Finally, the plan expansion and plan retrieval modules expand the inserted goals.
-
-
Future Work:
- Our techniques still have several limitations. Currently, our plan adaptation techniques require a plan to be fully instantiated in order to be adapted, thus we cannot adapt plans that are still half expanded.
-
As a consequence, the high level structure of the plan cannot be adapted unless it’s fully instantiated.
- This could be addressed by reasoning about interactions between higher level goals, by estimating which are the preconditions and success conditions of such goals by analyzing the stored plans in the case-base to achieve those goals.
- Another line of further research is to incorporate ideas from MPA in order to be able to merge several plans into a single plan.
- This can be very useful and can increase vastly the flexibility of the approach since sometimes no single plan in the case base can achieve a goal, but a combination will.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}